




Random Forests and Decision trees are the most prominent decision-making algorithms used in Machine Learning. Imagine making choices at each step, with a simple map guiding you—this is the essence of a Decision Tree. Now, picture having a whole team of experts advising you at every turn—that’s what a Random Forest offers. Both of them are influential machine learning algorithms with absolute capabilities. In this comprehensive blog, we will explore the capabilities of Random Forest and Decision Tree algorithms, their unique features, and user cases.
The comparison between the random forests and decision trees is not merely academic, they have some serious implications. For example, the benefit of using decision trees is that it is way more easier to understand and visualize offering higher accuracy and robustness, especially in the case of vast and complex datasets.
As a result, there’s constant debate, misunderstanding, and differing views over which is preferable: decision trees or random forests. In order to assist you in making wise decisions for your machine learning projects, we will examine the capabilities, unique features, and use cases of the Random Forest and Decision Tree algorithms in this blog.
What is Random Forest?
Random forest machine learning algorithm is mostly used for classification (categorizing data) and regression tasks (predicting continuous values). Random Forest also known as Random decision forest is an ensemble machine learning technique used for classification and regression tasks. Multiple decision trees are built during the training process.
For classification, each tree in the forest votes for a class, and the class with the most votes becomes the final prediction. In simple words, a random forest combines the output of multiple decision trees to derive one single result. This method helps improve accuracy and robustness by averaging the results of multiple trees.
Please note that the Random forest algorithms have three major hyperparameters. These hyperparameters are required to be set up before training. After setting these hyperparameters, the random forest classifier can be used to solve regression or classification problems.
In the below diagram, you can see the collection of decision trees, each built from a different subset of the training data using bootstrap sampling. Each tree makes decisions based on randomly selected features, contributing to the diversity of the forest. For predictions, the diagram will depict how, in classification tasks, the majority vote from all trees determines the final class, while in regression tasks, the average of all tree predictions is used.


What is a Decision Tree?
A decision tree is a type of supervised learning algorithm that doesn’t rely on a fixed set of parameters. Decision Tree algorithm is also used for both classification (categorizing data) and regression (predicting continuous values) tasks. The tree splits data into branches based on feature values, making decisions at each node until it reaches a final prediction at the leaves.
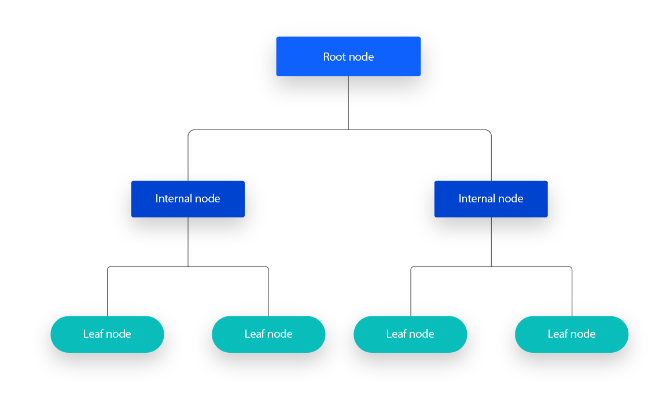
Simply put, decision trees have a hierarchical tree-like structure, which consists of a root node, branches, internal nodes, and leaf nodes.
In the below figure, a decision tree starts with a root node and doesn’t have any incoming branches. There is another outgoing branch from the root node that leads to internal nodes, these nodes are called decision nodes that make decisions based on available features to generate uniform groups. These groups end at the leaf nodes or terminal nodes. The leaf nodes represent all the possible outcomes in the dataset.

Random Forest vs Decision Tree – Brief Comparison
| Aspect | Random Forest | Decision Tree |
| Structure | Consists of a collection of decision trees | Composed of a single decision tree |
| Ease of Understanding | Less straightforward and complex due to the combined decision of multiple trees | Easily understandable & can be visualized in a single structure |
| Risk of Overfitting | Lower risk due to the aggregation of multiple trees | More risk, especially with deeper trees |
| Training Duration | Consumes more time as it includes building several trees | Faster to train as it involves only one tree |
| Reaction to Data Changes | More stable and less affected by small data changes due to averaging. | Sensitive to changes and noise in the data. |
| Speed of Prediction | Generally slower because of the aggregation of results from multiple trees | Smooth and fast predictions because it relies on a single tree |
| Effectiveness | Works well with larger datasets and complex problems | Suitable for both small and large datasets |
| Robustness to Outliers | More resistant to outliers due to ensemble averaging | More affected by outliers, which can skew results |
| Feature Evaluation | Determines feature importance through the combined decision of all trees | Provides direct feature importance, which may be less consistent |
Random Forest vs Decision Tree – Advantages & Disadvantages
Since this blog is about random forest vs decision tree, here’s the brief comparison of advantages and disadvantages of these two machine learning algorithms:
Advantages of Random Forest Machine Learning Algorithm
- Higher Accuracy: Leveraging several decision trees, each one trained on a different data subset, Random forest aggregates their predictions. Random Forest reduces the variation associated with individual trees. This helps to generate more accurate predictions, by averaging (for regression) or voting (for classification) the predictions of these trees. When using an ensemble approach instead of a single decision tree model, accuracy is typically higher.
- Resilience to Data Noise: The random forest machine learning algorithm is particularly suitable for noisy data as it uses various decision trees to make predictions. When the data has errors and outliers, the issues usually impact only a few of the individual trees.
- Non-Parametric Nature: The Random Forest algorithm follows a non-parametric approach. In simple words, it makes no prior assumptions regarding the distribution of data or about the connection between the target variable and its features. This flexibility proves that Random Forest can be applied to a vast range of datasets and problem domains. This enables the effective detection of complex patterns in the data without strict constraints.
- Estimating Feature Importance: Random forest calculates the importance of the features while also considering the relative contributions of every feature to the total variance (for regression) or impurity reduction for the classification of all the trees in the forest.
- Handling missing data: To handle missing data and outliers, Random Forest does not require the use of data preprocessing techniques such as imputation or outlier removal. A random subset of the input is used to train each decision tree and the method automatically deals with missing values. Outliers have less of an impact on the model’s overall performance since it is improbable that they will influence the forecasts of every tree in the forest.
- Handles both numerical and categorical data: Random Forest can handle combinatorial and categorical features without the need for feature engineering techniques like one-hot encoding. Because the approach automatically selects random subsets of characteristics for each decision tree during training, it can handle both data types without bias.
Disadvantages of Random Forest Machine Learning
- Complexity and Interpretability: Random Forest models are complex and relatively less interpretable compared to individual decision trees. The mutual decision of many trees can take time to comprehend and explain. While individual decision trees are easily interpretable, Random Forests, as an ensemble method, lose this transparency.
- Longer Trained Algorithms: Random Forest requires much more time to train as compared to decision trees as it generates a lot of trees (instead of one tree in the case of a decision tree) and makes decisions on the majority of votes.
- Memory Usage: Random Forest models are capable of using a lot of memory, especially when there are big datasets or deeply rooted trees. The ideal utilization rises as the number of trees or the depth of the trees, this results in limiting the memory on some hardware systems.
- Prediction Time: Despite being better at training, Random Forest models make prediction slower than some other algorithms. This is especially valid for models with a large number of trees or huge datasets. Every observation has to make its way through several decision trees in the forest to obtain a final forecast. This could increase the prediction time, particularly for applications that need to respond quickly or with low latency.
- Overfitting: Random Forest models may experience overfitting if they learn the noise present in the training data, which can hinder their ability to generalize effectively to new data. This tendency to overly fit the training data can diminish their predictive accuracy when applied to unseen instances, thus impacting their performance in real-world applications.
Advantages of Decision Tree Machine Learning Algorithm
- Interpretability: The interpretability of decision trees is one of the main advantages. The decision rules learned by the algorithm are simpler to explain to non-technical stakeholders. The transparency offered by the Decision tree is useful in industries such as finance and healthcare where healthcare is crucial.
- Non-linear relationships: Non-linear correlations between features and the target variable can be captured via decision trees. Decision trees work well with datasets that contain complicated patterns because, in contrast to linear models, they may reflect complex decision boundaries.
- No feature scaling required: No feature scaling is necessary because decision trees are not sensitive to the size of the features. This means that, unlike some other algorithms like Support Vector Machines or K-Nearest Neighbours, decision trees do not require feature scaling (e.g., normalization or standardization).
- Handles both numerical and categorical data: Decision trees don’t require one-hot encoding or other preprocessing methods to accommodate both numerical and categorical features. They are therefore useful for datasets including a variety of data types.
- Resilient to outliers: Decision trees are resilient to extreme and unusual data points. Simply put, decision trees can manage outliers effectively without having a major negative impact on their overall performance, in contrast to certain other algorithms that may exhibit strong influence from them. This is because outliers and splits based on feature values are produced by the tree structure.
Disadvantages of Decision Tree Machine Learning Algorithm
- Overfitting: While using decision trees, there are high possibility of overfitting, particularly when the data is way more noisy. A very deep tree will memorize all the training data and examples instead of learning general patterns, Techniques such as pruning (trimming the tree) or limiting its depth can help address this and enhance the generalization capacity of the model.
- High Variance: Decision Trees have high variance, meaning that slight changes in the training data can lead to very different tree structures. To address this issue and enhance performance, ensemble methods such as Random Forests or Gradient Boosting are commonly employed to reduce variance.
- Instability: Decision Trees can be sensitive to minor changes in the data, resulting in different splits and, therefore, different tree structures. This sensitivity can make them less reliable compared to other algorithms.
- Bias toward many features with various levels: In decision tree splits, features with a high cardinality (i.e., many levels) are typically preferred over features with fewer levels. The model’s performance may be impacted by this bias, particularly if the high-cardinality features don’t provide much useful information.
- Difficulty in capturing linear relationships: Random search are capable of capturing non-linear relationships, but it is difficult to capture linear relationships between features and the target variable for them. Other algorithms like linear regression may perform better in such cases.
Random Forest v/s Decision Tree- When To Use Which?
When To Use Decision Tree Machine Algorithm?
- For building simple models: Use Decision Trees for interpretable models where understanding the decision-making process is a key objective. For example, a Decision Tree might be used in healthcare to determine patient treatment options based on a few key factors, such as age and symptoms.
- For Small Datasets: Ideal for smaller datasets where you need a straightforward approach. eg- a decision tree could be leveraged in a small retail business to categorize the likes of customers based on a limited number of features.
- To Gain Quick Insights: Useful for rapid insights or setting up a baseline model. For instance, a startup might use a Decision Tree to analyze sales patterns quickly and set up initial predictive models.
- For Exploratory Analysis: A decision tree is also suitable for initial data exploration and understanding feature importance. An example would be using a Decision Tree to explore which factors most influence customer churn in a telecommunications company.
- Mixed data types: A decision tree is also a good fit for a combination of numerical and categorical features. It is capable of managing both types of features without the requirement of extensive preprocessing. It makes the modeling process simpler and more convenient for diverse datasets.
- Doesn’t require feature scaling: Decision Tree regression does not require feature scaling, such as normalization or standardization, because it is not affected by the scale of the features. This is beneficial in cases where it is difficult or unnecessary to scale features. For example, if your dataset includes features with very different units or magnitudes (like height in meters and weight in kilograms), Decision Tree regression can handle these differences directly. This makes it a good choice when scaling features would be impractical or when feature scaling does not add value.
When to Use Random Forest Machine Learning Algorithm?
- Complex Problems: Opt for Random Forests when dealing with large and intricate datasets where single Decision Trees might overfit. For instance, in the financial sector, Random Forests are utilized to forecast stock market trends by analyzing numerous variables and historical data.
- High Variance: Random Forests are particularly effective for managing high variance and enhancing model stability. In healthcare, they can predict disease outcomes using a broad range of patient data, providing more reliable results compared to single Decision Trees, which may be overly sensitive to data variations.
- Feature Importance: When a thorough evaluation of feature importance is needed, Random Forests excels. For example, in marketing, they can determine which factors (such as customer demographics or buying history) have the most influence on campaign success.
- No Need for Feature Scaling: Decision Tree regression doesn’t require feature scaling (like normalization or standardization) because it is not influenced by the scale of the features. This is advantageous when scaling features is challenging or unnecessary. For example, if your dataset includes variables with vastly different units or magnitudes (such as height in meters and weight in kilograms), Decision Tree regression can handle these disparities directly, making it a practical choice in such scenarios.
How to Implement Random Forest Classifier?
Step 1: Import Necessary Libraries
First, ensure you have the necessary libraries installed. If not, you can install them using pip:
bash pip install numpy pandas scikit-learn matplotlib seaborn
Next, import the required libraries:
python
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
import matplotlib.pyplot as plt
import seaborn as snsCode language: JavaScript (javascript)Step 2: Load and Prepare the Dataset
Load your dataset into a Pandas DataFrame. For this example, let’s assume you’re working with a CSV file:
python
# Load dataset
data = pd.read_csv('your_dataset.csv')
# Display the first few rows of the dataset
print(data.head())
# Handle any missing values
data = data.dropna()
# Split the dataset into features (X) and target variable (y)
X = data.drop('target', axis=1) # Replace 'target' with your actual target column name
y = data['target']Code language: PHP (php)Step 3: Split the Data into Training and Testing Sets
Divide your data into training and testing sets:
python X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
Step 4: Train the Random Forest Classifier
Initialize the Random Forest classifier and train it on the training data:
python
# Initialize the model
rf_classifier = RandomForestClassifier(n_estimators=100, random_state=42)
# Train the model
rf_classifier.fit(X_train, y_train)Code language: PHP (php)Step 5: Make Predictions
Use the trained model to predict the target variable for the test data:
python y_pred = rf_classifier.predict(X_test)
Step 6: Evaluate the Model
Assess the performance of the model using accuracy, a classification report, and a confusion matrix:
python
# Calculate accuracy
accuracy = accuracy_score(y_test, y_pred)
print(f'Accuracy: {accuracy}')
# Generate classification report
print(classification_report(y_test, y_pred))
# Generate confusion matrix
conf_matrix = confusion_matrix(y_test, y_pred)
sns.heatmap(conf_matrix, annot=True, fmt='d', cmap='Blues')
plt.xlabel('Predicted')
plt.ylabel('Actual')
plt.title('Confusion Matrix')
plt.show()Code language: PHP (php)Step 7: Hyperparameter Tuning (Optional)
To improve your model’s performance, you can fine-tune the hyperparameters using GridSearchCV or RandomizedSearchCV:
python
from sklearn.model_selection import GridSearchCV
# Define the parameter grid
param_grid = {
'n_estimators': [100, 200, 300],
'max_depth': [None, 10, 20, 30],
'min_samples_split': [2, 5, 10],
'min_samples_leaf': [1, 2, 4]
}
# Initialize GridSearchCV
grid_search = GridSearchCV(estimator=rf_classifier, param_grid=param_grid, cv=3, n_jobs=-1, verbose=2)
# Fit GridSearchCV
grid_search.fit(X_train, y_train)
# Get the best parameters
print(f'Best parameters: {grid_search.best_params_}')
# Use the best parameters to re-train the model
best_rf_classifier = grid_search.best_estimator_
best_rf_classifier.fit(X_train, y_train)
# Make predictions with the best model
best_y_pred = best_rf_classifier.predict(X_test)
# Evaluate the best model
best_accuracy = accuracy_score(y_test, best_y_pred)
print(f'Best model accuracy: {best_accuracy}')Code language: PHP (php)Step 8: Feature Importance (Optional)
To understand which features are most important for predictions, you can analyze feature importance:
python
# Get feature importances
feature_importances = rf_classifier.feature_importances_
# Create a DataFrame for better visualization
feature_importance_df = pd.DataFrame({'Feature': X.columns, 'Importance': feature_importances})
# Sort the DataFrame by importance
feature_importance_df = feature_importance_df.sort_values(by='Importance', ascending=False)
# Plot feature importances
plt.figure(figsize=(12, 6))
sns.barplot(x='Importance', y='Feature', data=feature_importance_df)
plt.title('Feature Importances')
plt.show()Code language: PHP (php)How to implement a Decision Tree for Machine Learning?
Step 1: Import Necessary Libraries
Start by installing the necessary libraries if you haven’t already:
bash pip install numpy pandas scikit-learn matplotlib seaborn
Next, import the required libraries:
python
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
import matplotlib.pyplot as plt
import seaborn as snsCode language: JavaScript (javascript)Step 2: Load and Prepare the Dataset
Load your dataset into a Pandas DataFrame. Here’s an example using a CSV file:
python
# Load dataset
data = pd.read_csv('your_dataset.csv')
# Display the first few rows of the dataset
print(data.head())
# Handle any missing values
data = data.dropna()
# Split the dataset into features (X) and target variable (y)
X = data.drop('target', axis=1) # Replace 'target' with your actual target column name
y = data['target']Code language: PHP (php)Step 3: Split the Data into Training and Testing Sets
Divide your data into training and testing sets:
python X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
Step 4: Train the Decision Tree Classifier
Initialize the Decision Tree classifier and train it on the training data:
python
# Initialize the model
dt_classifier = DecisionTreeClassifier(random_state=42)
# Train the model
dt_classifier.fit(X_train, y_train)Code language: PHP (php)Step 5: Make Predictions
Use the trained model to predict the target variable for the test data:
python y_pred = dt_classifier.predict(X_test)
Step 6: Evaluate the Model
Assess the performance of the model using accuracy, a classification report, and a confusion matrix:
python
# Calculate accuracy
accuracy = accuracy_score(y_test, y_pred)
print(f'Accuracy: {accuracy}')
# Generate classification report
print(classification_report(y_test, y_pred))
# Generate confusion matrix
conf_matrix = confusion_matrix(y_test, y_pred)
sns.heatmap(conf_matrix, annot=True, fmt='d', cmap='Blues')
plt.xlabel('Predicted')
plt.ylabel('Actual')
plt.title('Confusion Matrix')
plt.show()Code language: PHP (php)Step 7: Visualize the Decision Tree (Optional)
Visualizing the decision tree can help you understand how the model makes decisions. You can use the plot_tree function from scikit-learn:
python
from sklearn.tree import plot_tree
plt.figure(figsize=(20,10))
plot_tree(dt_classifier, filled=True, feature_names=X.columns, class_names=str(np.unique(y)))
plt.title('Decision Tree')
plt.show()Code language: JavaScript (javascript)Step 8: Hyperparameter Tuning (Optional)
To improve your model’s performance, you can fine-tune the hyperparameters using GridSearchCV:
python
from sklearn.model_selection import GridSearchCV
# Define the parameter grid
param_grid = {
'max_depth': [None, 10, 20, 30],
'min_samples_split': [2, 5, 10],
'min_samples_leaf': [1, 2, 4]
}
# Initialize GridSearchCV
grid_search = GridSearchCV(estimator=dt_classifier, param_grid=param_grid, cv=3, n_jobs=-1, verbose=2)
# Fit GridSearchCV
grid_search.fit(X_train, y_train)
# Get the best parameters
print(f'Best parameters: {grid_search.best_params_}')
# Use the best parameters to re-train the model
best_dt_classifier = grid_search.best_estimator_
best_dt_classifier.fit(X_train, y_train)
# Make predictions with the best model
best_y_pred = best_dt_classifier.predict(X_test)
# Evaluate the best model
best_accuracy = accuracy_score(y_test, best_y_pred)
print(f'Best model accuracy: {best_accuracy}')Code language: PHP (php)Summary
So, by now you must’ve understood the major differentiators between Decision Tree and Random Forest. In the above comparison of Random Forests and Decision Trees, we have stated the distinguishing capabilities and characteristics of these two popular machine learning algorithms. Decision trees are simpler and less complex in terms of interpretability and generating quick insights. It makes the decision tree algorithm more suitable for situations where understanding the decision-making process is pivotal. They are however prone to overfitting and sensitive to data changes. On the contrary, Random Forests provide higher accuracy, robustness to outliers, and resilience to data noise, making them a great fit to complex and large datasets. They mitigate the overfitting risk by aggregating the results of multiple trees, although at the cost of increased complexity and interpretability challenges.
Choosing between Random Forest and Decision Tree algorithms ultimately depends on the specific requirements of your project. If interpretability and rapid insights are priorities, a Decision Tree might be the better choice. For higher accuracy and handling complex datasets, Random Forests are preferable.
Understanding these differences empowers you to make informed decisions in your machine learning endeavors, leveraging the strengths of each algorithm to achieve optimal results.