




Have you ever thought about how quickly your smartphone recognizes faces in photos or suggests text as you type? Behind these features, there’s a remarkable technique called Transfer Learning that expands the capabilities of Artificial Intelligence. Now you must be wondering- What is Transfer Learning ? Picture this: Instead of starting from the square from scratch with every new task, what if AI models could learn from past experiences to solve the newly emerged challenges? In this guide, we will understand what transfer learning is, how transfer learning works, and the scope it opens for building smarter and efficient AI. We have also demonstrated how to implement transfer learning in Python but before jumping on to that, let’s get clarity on what is transfer learning.
What is Transfer Learning?
Transfer Learning is a deep-learning technique in Artificial Intelligence (AI). In transfer learning technique, a model trained for a specific task is remodeled or fine-tuned to do other related tasks by leveraging the data or knowledge it gained from the previous task. Simply put, transfer learning makes the learning process for new tasks more efficient and faster especially if the model has limited data.
The transfer learning approach has gained immense recognition in the areas of computer vision, Natural Language Processing, and many others.
What is Transfer Learning With Example:
Now, Let’s consider a common example in the field of computer vision to understand what transfer learning is:
Imagine you have a pre-trained CNN (convolutional Neural Network) model trained on a large dataset like ImageNet to identify various objects like birds, animals, and plants. Now, suppose you have a different task of recognizing different species of flowers, but you only have a relatively small dataset of flower images.
So, now you can utilize transfer learning to finetune your model instead of training a new CNN model from scratch on this small dataset. Please note that training a new CNN model can lead to overfitting. This is because of the availability of limited data, so leveraging transfer learning for your pre-trained CNN model and fine-tuning it on your flower dataset is a more convenient option.
While fine-tuning the model, keep the initial CNN layers fixed, securing ImageNet’s knowledge. Then modify later layers for specific flower species features. After this, modify or rearrange the later layers. This will make them efficient in recognizing features specific to various flower species.
Utilize the pre-trained model’s knowledge of general visual features and fine-tuning it on the flower dataset. By doing this, you can achieve better performance and faster convergence compared to training a CNN from scratch. This is a prime example of how transfer learning enables AI models to adapt and excel at new tasks by building upon existing knowledge.
So, now that you’ve understood What transfer learning is, Now it’s time to learn more about its implementation. In this blog, we are going to explain you How transfer learning works, how to implement transfer learning in Python. Continue reading..
How Does Transfer Learning Work?
Transfer Learning is a game-changer in the world of Artificial Intelligence. It stands as a shortcut to learning for AI models. Mostly, Computer vision and natural language processing tasks, such as sentiment analysis, mostly use transfer learning as they rely on vast computational resources.
Now it’s time to understand How Transfer learning works.
At its core, Transfer learning works on the principle of knowledge transfer. In computer vision tasks like image recognition, neural networks are organized in layers. Each layer is responsible for identifying and detecting the features within the input image. In the initial layers, the networks learn to recognize primary features like edges and textures. Deeper layers further extract more complex shapes and patterns. As the recognition process continues, the network actively filters its knowledge to understand and identify the objects based on the task it needs to complete.

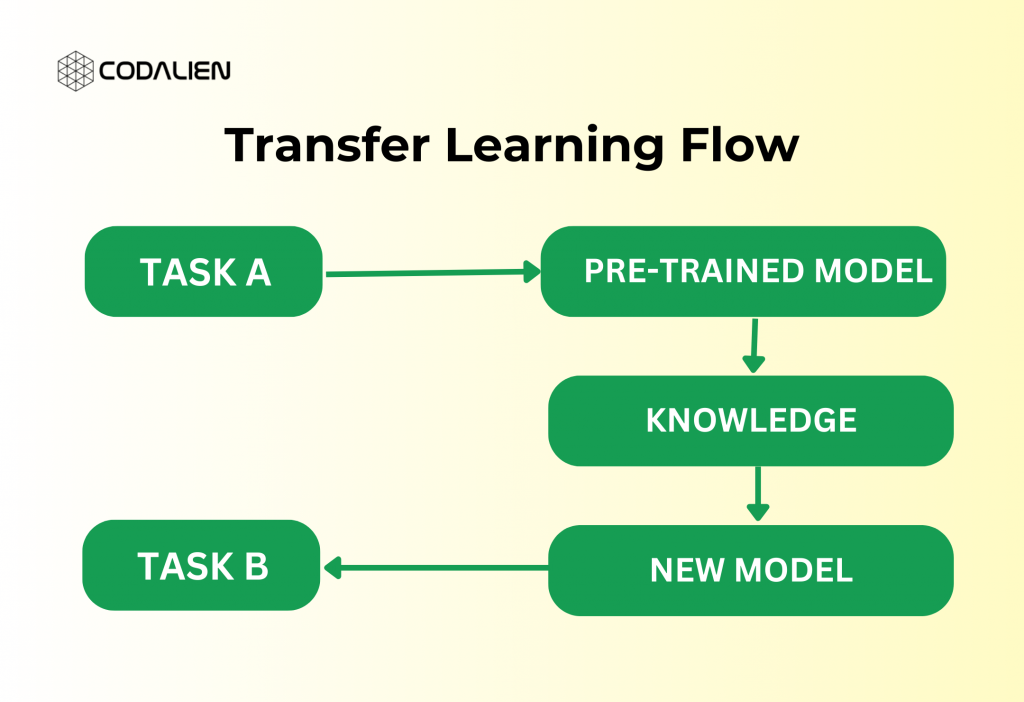
Explaining How Transfer Learning Works With Example
Let’s take an example to understand this how transfer learning works more comprehensively:
Imagine you have a pre-tra
ined model that classifies images of various types of clothing items like shirts, tops, pants, shoes, etc. But we want to repurpose this model to recognize the various types of flowers like roses, daisies, lilies, sunflowers, etc. So now, in the initial layers of the neural network of the model, it will identify the various visual patterns. These patterns may be the color, texture, and shapes which are common in all types of objects whether they are clothing items or flowers. These early layers will contain valuable data or we can say knowledge of these general visual features.
Now we would implement the transfer learning. In this step, we would retain these early layers. These layers already contain information on the fundamental visual characteristics (color, texture, and shapes). However, the later layers need to be retrained. These later layers are responsible for recognizing the more intricate features. These layers make them specialized in recognizing the species of the flower and be more specific about the tasks.
For retraining the later layers, we will have to provide a new dataset to the model that contains images of various types of flower species. In this step, we will fine-tune the pre-trained model’s later layers to gain knowledge of different features of various flowers like roses, tulips, lilies, and others.
This selective retraining process allows the model to adapt its learned features to the new task while leveraging the foundational knowledge acquired during the original training on clothing items.
During this selective retraining phase, the model makes use of the fundamental knowledge it learned during the initial training on clothing items to adapt its learned features to the current task.
Freezing Layers in Pre-Trained CNN Models
Gone are those days when developers used to painstakingly train the entire CNN model from scratch. Now, they mostly rely on pre-trained models, honed on large datasets. Some commonly used models are ImageNet’s 1.2 million images across 1000 categories to handle such tasks.
When we talk about transfer learning, there is a common concept we come across i.e. Freezing of Layers. But what does it mean?
In transfer learning, Freezing a layer means, locking the right of a layer (whether it’s a CNN layer, hidden layer, or block of layers). The layers are frozen to prevent them from being changed or updated during the training. While these layers remain frozen, the unfrozen layers continue to undergo the training process.
When employing transfer learning, we typically start with a pre-trained model as the foundational step. After this, we have two options of approaches to follow. We can either choose to freeze a certain layer of the pre-trained model while training the remaining layers as we have discussed previously. Or we can extract the specific features from the pre-trained model’s layers and implement them into a newly built model. In both cases, the ultimate goal is to preserve the learned features (which are relevant to performing the new tasks) from the pre-trained model while adapting the rest of the model to the new dataset requirements through training.
By implementing these strategic approaches, we can ensure that the pre-trained model only contains the most pertinent features. These features are aligned with the new tasks. This leaves the other model features to adjust and learn from the new dataset. In the end, transfer learning builds on the collective knowledge stored in pre-trained models enabling developers to handle a variety of tasks.

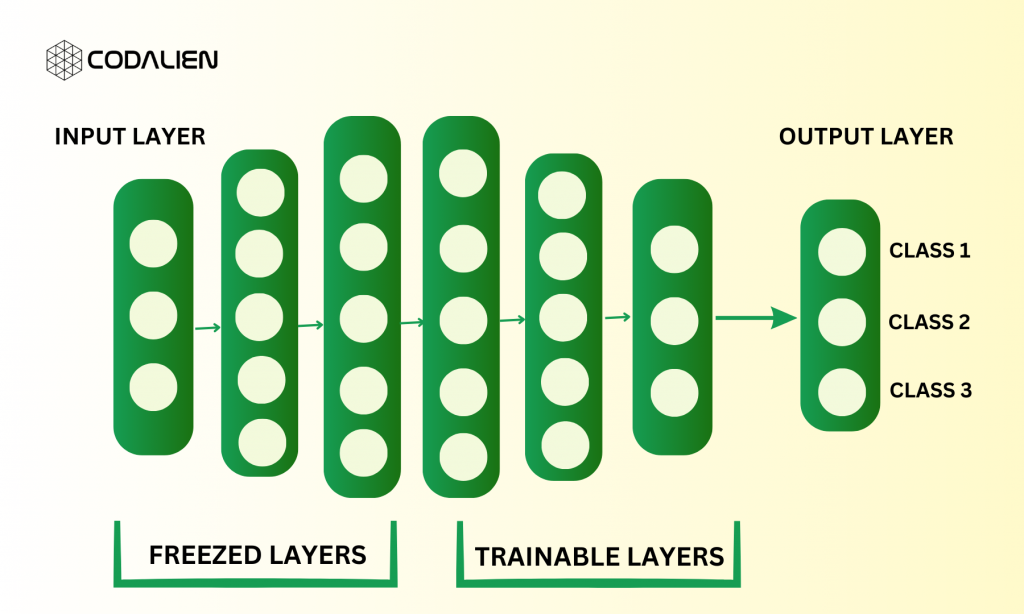
How To Determine Which Layers To Freeze in Transfer Learning?
In transfer learning, determining which layers to freeze and which to train can be confusing. It is based on the similarities between the new task and the pre-trained model’s knowledge or dataset. Suppose, the new task has many features in common with the pre-trained model, such as the detection of similar objects. In this case, we are going to freeze fewer layers to preserve the pre-trained knowledge. As in the previous example – detection of new flower species by leveraging a pre-trained model trained on flowers, we may only freeze a few layers to use its existing features.
When the new task is different from the previous task like identifying car models and names, freezing too many layers can be counter-productive. We will have to initially copy low-level features from the model. And then train the entire CNN on a new dataset. This will ensure that our model remains adaptable to new tasks without incorporating any un-relatable and unnecessary features from the pre-trained model.
Determining Which Layers to freeze in Transfer Learning
Let’s examine how transfer learning adjusts to various conditions based on the size and characteristics of the target dataset compared to the pre-trained model:
(i) Small Target Dataset, Similar to Base Network Dataset:
- When your target dataset is small but has common features with the foundational network’s dataset, fine-tuning the pre-trained network with the target data is recommended. However, there might be chances of overfitting in this case.
- To overcome the challenge of overfitting, we particularly eliminate the fully connected layers from the end of the pre-trained model, and their place is taken by a new fully connected layer that is suitable for the number of classes in the target task.
- Only the recently added layers are trained on the target dataset; the rest of the model features remain frozen.
(ii) Large Target Dataset, Similar to Base Training Dataset:
- In cases where the target dataset is large and matches the base training dataset, there’s very little chance of overfitting.
- Similar to the previous case of a small target dataset, we remove the entire connected layer and replace it with a new one built into the target task’s classes.
- However, the entire model is trained on the new dataset while keeping the architecture intact.
(iii) Small Target Dataset, Different from Base Network Dataset:
- Using high-level characteristics from the pre-trained model could not be helpful if the target dataset is considerably different from the dataset used in the base network.
- To accommodate the classes in the target dataset, additional layers are added after the majority of the pre-trained model’s layers are deleted.
- The pre-trained model’s low-level features are used, and the remaining layers are trained to match the new dataset. It can often be beneficial to train the entire network after a new layer is added.
(iv) Large Target Dataset, Different from Base Network Dataset:
- When the dataset is both large and distinguishable from the base network’s dataset, the best approach is to replace the last layers of the pre-trained network with new layers relevant to the target task.
- After this, the entire network is trained but you do not need to freeze any layer to ensure efficient adaptation to the new dataset.
Transfer learning serves as a rapid and effective starting point for various problems, providing guidance and often yielding superior results.
What are the advantages of Transfer Learning in Deep Learning?
As you might have guessed till now, there are numerous advantages of transfer learning, reduced training time is certainly one of the main advantages of Transfer learning. Apart from this, there are several other benefits of using transfer learning which are also listed below:
(i) Transfer Learning for Reduced Training Time
You can utilize the capabilities of pre-trained models that have already been trained on vast datasets by applying the transfer learning technique. By leveraging the knowledge already encoded in these models, you can save time and computational resources. Pre-trained models, trained on vast datasets, unlock potential through transfer learning.
(ii) Enhanced model Performance due to limited data
With transfer learning, information can be transferred from a target domain (where labeled data is limited) to a source domain (where labeled data is rich). Since the learned representations of the pre-trained model can transfer effectively to new tasks. Hence it requires less data, this is especially useful when working with small amounts of labeled data.
(iii) Effective-Feature Extraction With Transfer Learning
Pre-trained model, particularly the one that are trained on vast datasets such as ImageNet, have knowledge of rich and meaningful feature representations from raw data. You can efficiently utilize the high-quality features by fine-tuning or making these pre-trained models adaptable to new tasks. This will improve the performance of your model on your desired task.
(iv) Domain Adaptation
With transfer learning, the adaptation of models trained on a specific domain to perform well on another domain, This is specifically useful when the source and target domains have some underlying common similarities. However, it might be different in some aspects like different data distributions and imaging conditions.
(v) Overcome Overfitting
Transfer Learning helps to address the overfitting, particularly when we have limited training data. Starting with the pre-trained weights that store general patterns from a bigger dataset. In such a scenario, the chances of the model overfitting to the limited target domain are relatively lower.
(vi) Facilitates Research & Experimentation
Pre-trained models are the resourceful starting points for practitioners and researchers. It enables them to effectively prototype, experiment with various architectures, and fine-tune the relevant parts of the model to fit their specific needs.
What are the disadvantages of Transfer Learning?
While transfer learning is a brilliant technique in deep learning, however, there are several disadvantages of transfer learning as mentioned below:
(i) Domain Mismatch in Transfer Learning:
Transfer learning depends on the presumption that the source and target domains share underlying characteristics. The performance of the transferred model may be better if there is a substantial mismatch between the two domains, such as variations in data distribution, feature representations, or task objectives.
(ii) Limited Applicability of Transfer Learning
When applying pre-trained models to tasks or domains outside their original environment, they may need assistance to efficiently generalize to different tasks. It might hamper the performance due to their bias towards the source domain and fail to store or fetch the relevant features specific to the target domain.
(iii) Overfitting
Excessively fine-tuning the model on the second task can result in overfitting during transfer learning. This occurs because the model may learn task-specific features when fine-tuned excessively on the second task. This could be irrelevant knowledge that does not generalize well with the recent data.
(iv) Ethical Considerations
Implementing transfer learning has some ethical considerations. These concerns are related to the potential propagation of biases in the source data to the target task. This is because the biases present in the source data may transfer to the target task, and transfer learning presents ethical questions. When applied to new domains or populations, pre-trained models trained on large-scale datasets can inadvertently reinforce social biases inherent in the data, producing unfair or discriminatory results.
(v) Lacks Transparency
Pre-trained models are relatively less interpretable in comparison to simpler models. This is because they have complex architectures and millions of parameters. Therefore, it can be challenging to understand how the transferred knowledge from the source impacts the model’s decision-making process further limiting the model’s interpretability.
(vi) Dependency on Pre-trained Models
High-quality pre-trained models are necessary for transfer learning, but they are only sometimes available or appropriate for certain tasks or domains. Not all scenarios will allow for the large computational resources and labeled data needed to build unique pre-trained models.
Common applications and examples of transfer learning in neural networks
Transfer Learning has become quite popular across various domains and applications in neural networks. Some common applications of transfer learning are listed below:
(i) Transfer Learning for Image Classification
Tasks like image classification use transfer learning. In these tasks, we fine-tune pre-trained convolutional neural networks (CNNs) like VGG, ResNet, Inception, and MobileNet on specific datasets including CIFAR-10, CIFAR-100, or custom datasets to classify images into different categories.
(ii) Object Detection
Pretrained CNNS are used as feature extractors in object detection tasks to detect and localize within images. Various models such as Faster R-CNN, SSD (Single Shot Multibox Detector) and YOLO (You Only Look Once) can take advantage of transfer learning by using weights from pre-trained models such as RestNet or MobileNet for initializing the backbone network.
(iii) Semantic segmentation
Semantic segmentation tasks include tasks such as detecting pixels corresponding to objects or regions of interest within an image. You can segment images into distinct semantic categories by leveraging transfer learning. Pre-trained models such as U-Net, FCN (Fully Convolutional Network), and DeepLabv3 are used to extract features before fine-tuning for segmentation tasks.
(iv) Natural Language Processing
In NLP applications, practitioners use transfer learning with pre-trained language models like BERT, GPT, and RoBERTa. They refine these models on specific text datasets to make them suitable for future tasks like sentiment analysis, text classification, and named entity recognition. To make these models suitable for tasks further down the line, they are refined on certain text datasets.
(v) Speech Recognition
Automatic speech recognition (ASR) systems perform better when transfer learning is used for speech recognition tasks. To reliably identify spoken words and phrases, pre-trained models like WaveNet and DeepSpeech are refined using speech datasets.
(vi) Medical Imaging
In medical imaging applications, medical practitioners commonly use Transfer Learning. They leverage it to develop models to perform tasks like disease diagnosis and tumor detection. They fine-tune pre-trained Convolutional Neural Networks (CNNs) on medical imaging datasets. This leverages learned features, improving diagnostic accuracy.
(vii) Recommendation Systems
Transfer learning is also used for building efficient recommendation systems. These recommendation systems aim to deliver personalized recommendations to users based on their interaction and user behavior. In this use case, we fine-tune the pre-trained convolutional neural networks (CNNs) on user interaction data, so it can learn user embeddings and enhance recommendation quality.
(viii) Anomaly Detection
In anomaly detection tasks, transfer learning enables the identification of unusual patterns or outliers in data. Developers modify pre-trained models to identify anomalies in a variety of fields, including financial transactions, manufacturing processes, and network traffic.
How to Implement Transfer Learning in Python?
Now let’s explore, how to apply transfer learning in Python. Before you begin writing the code to implement transfer learning in Python, you need to do the following things:
1. Pre-requisites
Step 1: Install TensorFlow
First, ensure that TensorFlow is installed on your system. TensorFlow is a widely used open-source framework in Machine Learning. It simplifies complex tasks by offering a variety of functions that can be executed with just a single line of code.
Step 2: Import the necessary libraries and functions
!pip install tensorflow
Start with importing the libraries and functions we need. Additionally, we’ll import the MNIST dataset, which contains handwritten digits and is commonly used to train and test machine learning models.
Python3:
import tensorflow as tf
from tensorflow.keras import layers, models, optimizers
from tensorflow.keras.datasets import mnist
from tensorflow.keras.utils import to_categorical
Code language: Python (python)Step 3: Load and Unpack the MNIST Dataset
Next, let’s load and unpack the MNIST dataset into separate sets for training and testing. This includes images (x) and their corresponding labels (y).
Python3:
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train = x_train.astype('float32') / 255.0
x_test = x_test.astype('float32') / 255.0
Code language: Python (python)Step 4: Convert Class labels into one-hot encoded vectors
Now, let’s convert the class labels into one-hot encoded vectors for both the training and testing sets.
Python 3:
y_train = to_categorical(y_train, 10)
y_test = to_categorical(y_test, 10)
Code language: Python (python)2. Implementing MobileNetV2 for Image Feature Extraction: Pretrained Model Setup without Classification Layer
Import a MobileNetV2 model that’s already been trained, but skip the part that categorizes images. With TensorFlow/Keras, the code sets up the MobileNetV2 model with input dimensions of (224, 224, 3). This removes the top layers for feature extraction, and employs pre-existing ImageNet weights. This setup is perfect for tasks such as transferring knowledge to new image classification tasks.
Python 3:
base_model = tf.keras.applications.MobileNetV2(input_shape=(224, 224, 3),
include_top=False,
weights='imagenet')
Code language: Python (python)3. Adding Custom Layers on the Top of the Pre-trained model
This code utilizes TensorFlow’s Keras API to build a Convolutional Neural Network (CNN). It incorporates layers for reshaping, convolution, pooling, flattening, and fully connected operations, along with dropout for regularization purposes. The model employs softmax activation to generate class probabilities, making it relevant for image classification tasks, such as with the MNIST dataset. By striking a balance between feature extraction and categorization, this design facilitates effective learning and generalization.
Python 3:
model = models.Sequential()
model.add(layers.Reshape((28, 28, 1), input_shape=(28, 28))) # Add a channel dimension
model.add(layers.Conv2D(32, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Flatten())
model.add(layers.Dense(256, activation='relu'))
model.add(layers.Dropout(0.5))
model.add(layers.Dense(10, activation='softmax'))
Code language: Python (python)4. Freeze The Pre-Trained Layers
In transfer learning, Before compiling and training the model, it’s important to freeze the pre-trained layers. Freezing them means their weights won’t be changed during training, which is done by setting their trainable attribute to False. Since MobileNetV2 has many layers, setting the trainable flag of the entire model to False will freeze all of its layers.
Python 3:
for layer in base_model.layers:
layer.trainable = False
Code language: Python (python)5. Compiling The Model
Now, you must adjust the lower learning rate as you are training a relatively larger model requiring the re-adjustment of pre-trained weights. In case you do not do so, it could lead to rapid overfitting.
model.compile(optimizer=optimizers.Adam(learning_rate=0.001),
loss='categorical_crossentropy',
metrics=['accuracy'])
Code language: Python (python)6. Custom Training Loop
The process in which you manually iterate over batches of data, compute gradients, and update model parameters outside of the standard fit() method provided by TensorFlow, is called “custom training loop.” This approach offers more flexibility and control over the training process compared to using the built-in training routines.
This script in TensorFlow is for training a neural network across several epochs. It relies on two datasets: one for training (train_dataset) and the other for validation (val_dataset). During each training loop iteration, it calculates the gradients of the categorical cross-entropy loss and adjusts the model’s weights using the Adam optimizer. After completing each epoch, a separate loop evaluates and displays the validation accuracy. It’s worth noting a slight adjustment: initializing the optimizer outside the training loop ensures it functions correctly.
Python 3:
epochs = 10
batch_size = 32
# Create tf.data.Dataset for training and validation
train_dataset = tf.data.Dataset.from_tensor_slices((x_train, y_train)).shuffle(60000).batch(batch_size)
val_dataset = tf.data.Dataset.from_tensor_slices((x_test, y_test)).batch(batch_size)
for epoch in range(epochs):
print(f"Epoch {epoch + 1}/{epochs}")
# Training loop
for images, labels in train_dataset:
with tf.GradientTape() as tape:
predictions = model(images)
loss = tf.keras.losses.categorical_crossentropy(labels, predictions)
gradients = tape.gradient(loss, model.trainable_variables)
optimizer = optimizers.Adam(learning_rate=0.001)
optimizer.apply_gradients(zip(gradients, model.trainable_variables))
# Validation loop
accuracy = tf.metrics.CategoricalAccuracy()
for images, labels in val_dataset:
predictions = model(images)
accuracy.update_state(labels, predictions)
val_acc = accuracy.result().numpy()
print(f"Validation Accuracy: {val_acc}")
Code language: Python (python)And this will be the output:
Output:
Epoch 1/10 Validation Accuracy: 0.972000002861023 Epoch 2/10 Validation Accuracy: 0.9700999855995178 Epoch 3/10 Validation Accuracy: 0.951200008392334 Epoch 4/10 Validation Accuracy: 0.9736999869346619 Epoch 5/10 Validation Accuracy: 0.9782000184059143 Epoch 6/10 Validation Accuracy: 0.9800000190734863 Epoch 7/10 Validation Accuracy: 0.9787999987602234 Epoch 8/10 Validation Accuracy: 0.9740999937057495 Epoch 9/10 Validation Accuracy: 0.9782999753952026 Epoch 10/10 Validation Accuracy: 0.9786999821662903
7. Evaluate the model’s performance on the test set
Now, let’s assess the model’s performance using the test dataset:
test_loss, test_accuracy = model.evaluate(x_test, y_test)
print(f"Test Accuracy: {test_accuracy}")Code language: PHP (php)Output:
313/313 [==============================] - 5s 13ms/step - loss: 0.4465 - accuracy: 0.9787
Test Accuracy: 0.9786999821662903Code language: Python (python)Frequently Asked Questions (FAQs)
1. What is Transfer Learning?
In transfer learning with neural networks, we apply pre-trained models, initially trained on large datasets for a specific task, to solve another problem. This involves reusing the learned representations within those models. Typically, a pre-trained model undergoes training on a large dataset for the source task before further training on a smaller dataset for a specific task.
It uses the knowledge and feature representations it has learned thus far. Even when the datasets or tasks are different, the target task can profit from the generalization and feature extraction skills acquired from the source job by utilizing the pre-trained model’s expertise.
2. How do you choose a model for transfer learning?
To choose a model for transfer learning, keep the following things in mind:
- Understand your task: Start by figuring out what your target task requires. Consider things like the type of data you’re working with (like images, text, or audio), what you want the model to do (classify, regress, segment), and any specific challenges in your domain.
- Look for similar tasks: Find pre-trained models that have been used for tasks similar to yours. These models may have already learned useful features that can be applied to your task.
- Evaluate model performance: Test how well candidate models perform on tasks similar to yours. Look for models that are accurate, generalize well, and work across different datasets.
- Choose the right architecture: Pick a model architecture that fits your task and dataset. For example, if you’re working on image classification, popular architectures like VGG, ResNet, or MobileNet might be good choices.
- Consider size and complexity: Think about the resources you have available for training and running the model. Larger, more complex models might offer better performance, but they also require more computational power and memory.
- Check for pre-trained weights: Make sure that pre-trained weights are available for the model you choose and that they work with your deep learning framework (like TensorFlow or PyTorch). Pre-trained models trained on large datasets like ImageNet often provide good starting points.
- Think about fine-tuning: Choose a model that allows you to fine-tune it for your specific task. Being able to freeze certain layers while fine-tuning others can help prevent overfitting. Fine-tuning
- Look for support and documentation: Make sure the model you choose has good documentation and support from the deep learning community. This will help you troubleshoot any issues and get guidance as you work on your task.
3. What are the types of Transfer Learning?
There are various types of transfer learning techniques, the most popular ones are: Instance-based transfer learning, Feature base transfer learning, Model based transfer learning, Domain based transfer learning, Sequential transfer learning, and Fine tuning. Let’s understand the types of transfer learning properly:
Types of Transfer Learning
(i) Instance-based Transfer Learning: This method trnsfers information from examples or instances in the source domain to examples in the destination domain. This could entail training a model for the target domain directly, with potential adaptations or fine-tunings, using labeled examples from the source domain.
(ii) Feature-based transfer learning: It involves transfer in the form of gained features from the source domain to the target domain is known as feature-based transfer learning. Pre-trained models, particularly those trained on extensive datasets such as ImageNet, gain knowledge of rich feature representations that can be transferred for new tasks or domains.
(iii) Model-based Transfer Learning: In model-based transfer learning, the entire model or its part is moved to the target domain from the source domain. This approach may involve transferring the architecture and weights of a pre-trained model or it could entail adapting only some specific layers or components of the model to the target task.
(iv) Domain-based Transfer Learning: Domain-based transfer learning transfers knowledge between domains. Domains may differ in data distribution or task objectives. Techniques like domain adaptation align source and target domain distributions. This improves performance on the target task.
(v) Sequential Transfer Learning: Transferring information from several source domains or tasks to a single target domain or activity is known as sequential transfer learning. This could entail using information from several source tasks at once to enhance performance on the target task, or it could entail adapting to the target domain first and then transferring knowledge from one source domain to another.
(vi) Fine-Tuning: Fine-tuning is a widely used technique in transfer learning. In this technique, a pre-trained model is adjusted using task-specific data to fit its parameters to the intended job. The model learns task-specific attributes through fine-tuning while retaining the general information gained from the source domain.
4. How does transfer learning benefit the training of AI models?
Transfer learning benefits the training of AI models in various ways which are:
(i) Reduced Training Time and Resources
(ii) Better Generalization
(iii) Enhanced Performance
(iv) Domain Adaptation
(v) Addressing Data Security
(vi) Flexibility and Versatility