




When you engage with ChatGPT or any other Generative AI tool, you just type and enter your query and Tada!! You get your answer in seconds. Ever wondered how it happens and how it is so quick? Let’s peel back the curtain of the LLMs a bit. What actually happens behind the screen is a lot more complex! Think of it like this: We have a whole set of steps in place, a well-organized system that ensures ChatGPT or any other tool you’re using understands your question and processes it quickly and accurately. We call this robust system Large Language Model Operation (LLMOps), and it’s what keeps everything running seamlessly. Now you must be wondering what is LLMOps?
Well, In this blog, we are going to understand LLMOps. We will walk you through each step of the entire process, starting from when you type and enter your prompt to when you get your desired answer. So, let’s start our journey to the world of operationalizing LLM applications- and trust us, it is more interesting than you imagine.
What is LLMOps: Understanding The Foundations of LLMOps
Before understanding what is LLMOps, first, let’s understand what Large Language Models (LLMs) and Machine Learning (ML) are:
Large language models (LLMs) are like super-smart AI systems that can understand and generate human-like language. We call them “large language models” or LLMs because they undergo extensive training on massive amounts of text, such as books, articles, and websites, to grasp the intricacies of language. These LLMs are substantial, with billions of tiny parts called parameters, and they learn from billions of words during training. That’s why we call them “large language models”!
In the world of artificial intelligence (AI), Machine Learning (ML) stands out as a field that’s all about crafting algorithms capable of learning from data. These algorithms then use this knowledge to make predictions or decisions without needing explicit programming.
It fills the gap between the development and deployment of machine learning models. Just like DevOps focuses on the collaboration and automation between software development and IT operations, MLOps focuses on the collaboration and automation between data science, machine learning, and operations teams.
Large Language Model Operations (LLMOps) is a specialized subset of Machine Learning Operations (MLOps). We can also state that LLMOps is equal to MLOps, however, it’s specifically designed to manage the complexities of large language models (LLMs) such as those developed by Google or OpenAI.
LLMOps is essentially about streamlining the operational parts of large language model deployment and maintenance so that they seamlessly integrate into processes and applications in the real world.
Why LLMOps are important?
In our exploration of understanding LLMOps essentials, it’s imperative to grasp why LLMOps are important in the operationalization of LLMs. Let’s dive deeper into the importance of LLMOps for businesses and organizations who are looking to leverage the capabilities of LLMs effectively:
(i) Efficient Deployment & Management:
Operationalizing LLMOps is the process of integrating these complex models into practical applications. LLMOps makes this deployment procedure effective, smooth, and optimized for performance. LLMOps create the groundwork for the successful integration of LLMs into corporate operations by optimizing deployment workflows and efficiently allocating resources.
(ii) Scalability & Flexibility:
Businesses’ requirements for AI-driven language models are always changing and growing. Businesses may effectively scale their LLM deployments to meet increasing needs thanks to LLMOps. To support growing workflows and adjust to changing needs, LLMOps offers the scalability and flexibility required for managing higher workloads, entering new markets, or introducing new products.
(iii) Risk Mitigation:
As we know with great power comes great responsibility and even greater risks, LLMOps help in mitigating risks that come with the usage of large language models, these risks may include bias, ethical concerns, and security vulnerabilities. LLMOps help to avoid risks by rigorously monitoring, auditing, and governance protocols.
(iv) Cost Optimization:
Operating LLMs continuously and scaling them as per demand can incur some heavy costs concerning infrastructure and energy consumption. LLMOps employ techniques like model pruning, resource allocation strategies, and energy-efficient architectures to optimize costs without sacrificing performance.
(v) Adaptability & Evolution:
LLM technology is always evolving, with new models and methods appearing quickly. By making it easier to incorporate new developments into current workflows, LLMOps helps businesses maintain their innovative edge without causing any disruptions.
Inside LLMOps: Operationalizing Large Language Models
To understand LLMOps, you need to delve into the complex mechanisms that underlie LLMs when they function as utilities. This process entails following a prompt from input to answer. See the schematic representation below:

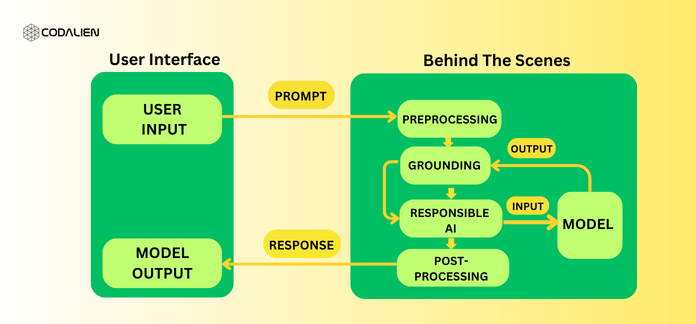
Stage 1: Pre-Processing
The first stage in LLMOps is preprocessing. In this step, user input is prepared for pre-processing before being sent to the language model. The preprocessing involves various tasks. These tasks ensure that the input remains in a format. This format allows the model to comprehend and process efficiently. These tasks include tokenization and data normalization. In tokenization, the prompt is classified into tokens, and in data normalization, it enables the identification of errors and standardizes the text. Encoding then translates tokens into a format intelligible to the model using embeddings.
Stage 2: Grounding in LLMOps
This step involves the contextualization of the prompt. It is like providing the language model a backstory to understand and work with. It involves referencing previous interactions or external data to ensure that the model’s answer blends in with the current discourse. Here, entity recognition and linking comes into the picture. Let’s say your prompt includes a name or location reference. The model must comprehend what or who you are referring to, as well as how it pertains to the discussion. Through this process, the model becomes able to understand the context and formulate a response that seems relevant and natural.
Stage 3: Responsible AI
Some services ensure LLM usage is well-intentioned by implementing sanity checks on user prompts. Typically, these services evaluate prompts to ensure safety and compliance guidelines, especially in cases involving sensitive information, inappropriate content bias, or misleading information.
The model then receives the prompt for processing only after these steps are completed. The response may repeat the Grounding and Responsible AI processes as well as an additional post-processing step once the model has generated it and before displaying it to the user.
Stage 4: Post-Processing
When the model gives a response, it doesn’t get displayed as words or sentences immediately. Instead, it is initially in a numerical format because of vector embeddings. The model translates this numerical representation into human-readable text through a process called decoding. However, once the model encodes the response, it still isn’t quite ready to send to the user. The model must refine the response to ensure it’s grammatically correct, has the right tone, and is easily understood. This includes fixing errors, adjusting the tone, or making small enhancements to make it easily readable and understandable.
Once all the above-mentioned things are done, the refined response is finally all set to be displayed to the user. The best part of this entire process is that all of these complex tasks happen behind the scenes, thanks to the LLMOps infrastructure. The user doesn’t need to go into the technical details. It’s like having a team of invisible helpers ensuring everything runs smoothly, so you can focus on the conversation at hand.
Understanding the Crucial Role of Latency in LLMOps for LLM Models
But how much time does this entire process take? Well, in LLMOps, the time taken by the LLM Model to give a response to the user after they submit the prompt to the model, is what we call latency. In simple words, we can refer to latency as the delay between inputting a query and getting a reply.
When we use mature models like ChatGPT, the response time is almost instant. This response time is called latency. And latency is a key performance metric, especially in user-facing applications where the time of response affects the user experience. Users feel satisfied and engaged when responses are prompt and easy to use. On the other hand, visible lag or delay might cause annoyance and discontent. Thus, maximizing the efficacy of user-facing programs and guaranteeing a satisfactory user experience depends on latency optimization.
How Does LLMOps Minimize the Latency To Improve The Performance of the LLM Model?
In order to minimize the latency, LLMOps employs various strategies and approaches to streamline the process, starting from when the user submits its input to the final delivery of the response. By automating key steps and managing resources effectively, LLMOps ensure that all computational tasks are completed promptly, without waiting for resources to become available.
(i) Caching: One such approach is caching. In this technique, we keep the computationally intensive parts and frequently accessed parts of the model’s output. This significantly reduces processing time because these items can be instantly accessed from memory instead of having to recalculate them for each request.
(ii) Concurrent Processing: Now this is yet another tactic used by LLMOps. LLMOps enhance resource utilization. They reduce waiting time by handling many requests at a time. This is particularly useful during peak demand periods. At such times, multiple users send requests concurrently. This enhances overall responsiveness.
(iii) Monitoring: LLMOps employs rigorous monitoring practices to continuously evaluate and optimize system performance. Through the process of profiling various model and infrastructure components, LLMOps is able to detect bottlenecks and inefficiencies, allowing for timely optimization in order to sustain ideal performance levels.
Choosing The Right Foundation Model in LLMOps
Now, let’s dive deep into the most important aspect of LLMOps setup. With a plethora of models available, each with its specific use case and different size and optimization levels. The choice should be based on our application and the availability of resources.
As the landscape and availability of LLMs keep expanding, it is crucial to gain a deeper understanding of various models and providers. So, let’s begin!
Types Of LLM Providers
Well, LLMs and providers can be classified into the following types:
(i) Proprietary Models:
Companies such as OpenAI (GPT models), Google (PaLM models), and Anthropic (Claude model), have developed proprietary models as a service. All of them use web interfaces or API endpoints.
(ii) Open-Source Models:
Now this category encompasses free models built and fostered by the community, academia, or entities. Some of the big organizations that build such models are Eleuther AI and Big Science. The open-source models usually rely on donations for computing infrastructure. These models offer the flexibility to engineer the service ourselves which also includes LLMOps infrastructure.
(iii) Companies Providing Infrastructure:
Some organizations specialize in offering LLMOps infrastructure for open-source LLMs, monetizing by offering deployment services like Together AI. Here, the company offers the chance for simple LLMOps infrastructure customization.
Proprietary Models v/s Open Source LLM Models: Which One is Better?
Let’s step into the ring and settle the age-old confusion: proprietary v/s open-source models, which one is better? It’s a battle where the winner is not always clear-cut. The decision comes down to no. of factors. so here we are briefly breaking down it for you:
| Feature | Open-Source LLM Models | Proprietary Models |
| Cost | Typically free to use and modify. May have associated costs for training or deployment. | Usually high licensing fees or subscription costs. |
| Transparency | Transparency in model architecture, training data, and development process. | Often lack transparency in terms of model architecture and training data. |
| Customization | High level of customization, allowing developers to tailor the model to specific needs. | Limited customization options, usually confined to provided APIs or interfaces. |
| Support | Relies on community support, but may have active developer communities and forums. | Typically offers professional support services. |
| Innovation | Innovation may be slower compared to proprietary models but benefits from a wider range of contributors and collaborations. | May have faster innovation cycles due to dedicated research and development teams. |
| Security | Security depends on community efforts and may not always be as robust as proprietary models. | Often have robust security measures in place to protect proprietary technology. |
| Data Privacy | Generally better data privacy as users have more control over data handling and storage. | Concerns regarding data privacy as proprietary models may collect and utilize user data. |
| Integration | Integration may require more effort but is generally flexible due to open APIs and interoperability. | Integration may be smoother with proprietary ecosystems and platforms. |
| Accessibility | Available to a wider range of users, including those with limited financial resources. | Access may be limited to users who can afford the costs. |
What are the factors to consider to select the right model?
When you want to select the right LLM model, there are several key factors to consider in order to make the right decision:
1. Purpose and Requirements:
Define the specific tasks you want your LLM to perform and consider the languages it should support and any other relevant criteria such as computational resources and performance metrics.
2. Research The Available Options:
Conduct in-depth research to understand the LLMs that are available and can meet your requirements. You should explore both proprietary and open-source options and make the choice while considering various factors. These factors may include model architecture, pre-trained capabilities, and community support.
3. Evaluate Performance:
Evaluate the performance of the LLMs based on the benchmark datasets or real-world tasks. Look for models that exhibit high levels of efficiency, accuracy, and robustness across a range of tasks and languages.
4. Resource Constraints (cost and resources):
Assess your computational resources such as budget and hardware capabilities. Opt for a model that can easily function within your resource constraints without compromising performance.
5. Customization & Flexibility:
When choosing an LLM model, you must consider the fact that whether you want a model that can be seamlessly customized or fine-tuned. Please, note that models that can offer your flexibility and scalability are crucial in dynamic environments.
6. Interpretability & Explainability:
A model that delivers interpretable or comprehensible outcomes might be necessary for your application, particularly in regulated industries or applications where transparency is crucial.
7. Scalability:
Go for an LLM model that is built for scalability and accommodates future growth especially if you are concerned about scaling your model to handle increasing data volumes or growing user demand.
8. Privacy & Security:
If you are going to handle some personal or sensitive data of users or your organization, it is important to evaluate the privacy and security implications. Choose a model that complies with the industry standards data security and privacy guidelines.
9. Long-Term Viability:
Evaluate the model’s long-term viability taking into account things like regular upkeep, updates, and support. Select a model that has demonstrated stability and has a roadmap for future development.
10. Community Support & Documentation:
Take into account the level of documentation and community support that the model has. A thriving community can offer helpful resources, tutorials, and support with troubleshooting.
11. Licensing:
Model selection that complies with our intended use is essential. Certain models may have limitations on particular use cases, even if they expressly permit commercial use.
For instance, the BigScience Open RAIL-M license restricts the usage of the LLM in domains concerning immigration, law enforcement, and asylum procedures, among others.
Fine-Tuning Strategies In LLMOps
Whether proprietary or open-source, organizations often need to fine-tune LLMs to suit their specific applications properly. Pre-fine-tuned LLMs cater to certain user tasks like chats, summarization, or sentiment analysis. However, Long-context models are an additional option to take into account. While the majority of modern LLMs can handle context lengths of between 2,000 and 8,000 tokens, some offer long-context variants, such as GPT-3.5’s larger 16K context size variant.
Nevertheless, if the existing or pre-built option doesn’t meet your requirements, there’s always the possibility of fine-tuning or even training a model yourself. In this situation, selecting the right dataset is crucial since it will help your model to understand the nature of the intended task.
Various Strategies of Fine-Tuning LLMs
1. Task-Specific Fine Tuning:
To make the pre-trained LLM adaptable for a certain task or application, fine-tune it with task-specific datasets. In order to do this, labeled examples related to the targetted task—such as sentiment analysis, text categorization, or language translation must be used to train the model.
2. Domain Adaptation:
Fine-tune your LLM model based on the domain-specific data as it will enhance its performance within a particular industry or domain. It may involve improving the model’s understanding of domain-specific vocabulary and terminology by training it on the text samples from the targetted domain.
3. Transfer learning:
You can use transfer learning techniques to fine-tune the pre-trained LLM models on the related tasks and domains before implementing them to the target task. In transfer learning, the LLM model is pre-trained on a vast, diverse dataset and then fine-tuned on smaller, task-specific datasets to transfer knowledge and features learned during pre-training
➤ Check out our latest blog on What is Transfer Learning and how it works? to gain an in-depth understanding of this technique in LLMOps.
4. Multi-Task Learning:
Train the LLM to perform numerous tasks at a time by jointly optimizing it for multiple objectives at a time. Multi-task learning is done by fine-tuning the LLM model on a dataset that includes examples from multiple tasks, allowing the model to learn common representations and features across the tasks.
5. Data Augmentation:
You can also augment the training data by applying different transformations or disorders to maximize the diversity and robustness of the dataset. Data Augmentation involves some techniques including adding noise, paraphrasing, or generating synthetic examples to improve the model’s generalization performance.
6. Ensemble Learning:
You can also combine multiple fine-tuned models to boost the overall performance of the model. Ensemble training involves training several LLMs with various hyperparameters or initializations and then assembling their predictions to make a final prediction.
7. Hyperparameter Tuning:
You can also optimize the hyperparameters of LLM’s fine-tuning process. These hyper-parameters include batch size, learning rate, and regularization strength. Please note that optimizing these hyperparameters helps in maximizing performance on the target tasks. To do this, try out several hyperparameter combinations and choose the ones that get the best results.
➡️ Check this out: Know more about Hyperparameter Tuning, Techniques, Strategies, and Frameworks
8. Continual Learning:
Allow the LLM to gradually adjust to new tasks or data without catastrophically forgetting what it has already learned. This entails methods like incremental fine-tuning, in which the model is re-trained on fresh data on a regular basis while retaining knowledge learned from previous training phases.
LLMOps-Driven Fine-Tuning To Enhance Your Model’s Performance
In the Operationalization of LLMs, precision and adaptability are always at the center stage, therefore fine-tuning existing models is a crucial step. Integrating model customization into your workflow enriches your toolkit ensuring that your model keeps evolving with your changing needs.

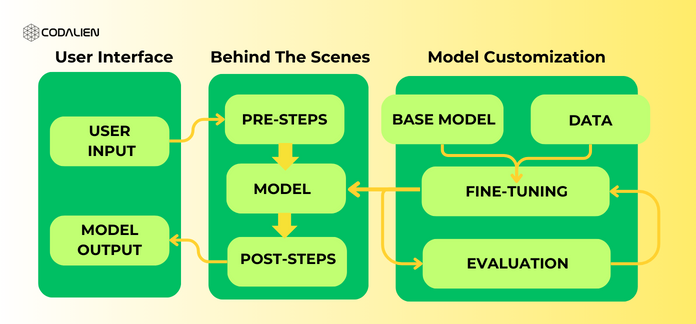
- Craft a refined pipeline
Establishing a consistent fine-tuning pipeline assists you with expanding your model’s knowledge over time as more data becomes available.
- Navigating Model Dynamics
We must anticipate shifts whether it is cost or availability while tethering to third-party models. A robust LLMOps setup acts as your guiding compass for model transitions when there’s a need by just replacing the “Model” box with a different LLM.
Training Data: Structure Formatting For Effective LLM Model Training
Training and fine-tuning LLMs may seem external to LLMOps infrastructure, but that’s not the case. They are vital for maintaining model resilience and effectiveness. Consistent data formatting between training and inference data is crucial for effective model training and refinement within a generic LLMOps framework.
JSON Lines Format:
You can use JSON Lines (.jsonl) format for fine-tuning and training LLMs. Using JSON lines offers several benefits in the LLMOps infrastructure as they facilitate seamless integration of fresh data into model training and effective organization of vast datasets.
Each line in a .jsonl file represents a single training example that has structured data with completion and prompt keys. This structure ensures consistency in data formatting which is essential for efficient model training and improvement in a generic LLMOps framework.
{"prompt": "Question: What is the capital of France?", "completion": "The capital of France is Paris."}
{"prompt": "Question: Who wrote Macbeth?", "completion": "Macbeth was written by William Shakespeare."}Code language: JSON / JSON with Comments (json)Each line in the style comprises a prompt, which is the input text or text or question, and a completion, which is the anticipated model response or answer. This kind of precise delineation facilitates the training process, enabling easy pairing of prompts with the appropriate completions.
Adopting JSON Lines simplifies processing speed, streamlines data management, and facilitates seamless integration of new training examples into the model’s knowledge base. The robustness and efficiency of LLMs within the LLMOps infrastructure are improved by this standardization of data formatting.
Maximizing LLM Efficiency: Understanding Parameters
Model parameters govern crucial aspects of LLMOps infrastructure including resource efficiency and model size. Achieving a balance between resource constraints, like memory utilization and model complexity is crucial when it comes to training parameters. This optimization ensures that models work practically and remain flexible in diverse deployment environments.
Inference parameters like as temperature and max tokens can control response qualities like duration and unpredictability. The output of the model is customized to meet specific application needs and user expectations with these LLMOps-managed settings.
Prompt Engineering Essentials To Enhance LLM Performance
Prompt engineering has proved to be effective in maximizing the efficiency of Large Language Models (LLMs). It contextualizes model behavior and directs outputs towards desired outcomes significantly enhancing performances. There are two proven effective prompt engineering practices that you can use within the LLMOps infrastructure: (i) Few-shot prompting and (ii) Chain-of-thought reasoning
(i) Few-shot prompting helps with task execution and comprehension by giving the LLM a small no. of task examples right within the prompt. This enables the model to understand and perform the specific task effectively.
(ii) On the other hand, chain-of-thought reasoning structures prompt to lead the model through a step-by-step logical reasoning process making it capable of handling complicated tasks.
Please note that you can use Prompt templates to incorporate these prompt engineering techniques within your LLMOps setup effectively.
Prompt Templates – What are Prompt Templates?
Prompt Templates are pre-defined structures that are used to provide direction to the reasoning of LLMs, specifically concerning prompt-based approaches. These templates ensure that similar types of requests are made evenly by offering a standard format for prompts or input queries.
How To Use Prompt Templates?
In prompt templates, we typically include slots or placeholders to store specific data or context. These placeholders consist of relevant details based on the user’s input. Users can communicate with the model in an organized manner making it simpler to specify their objectives and requirements.
For Instance, a prompt template for creating product descriptions might include a placeholder for product features, advantages, and specifications. Each placeholder will allow users to input specific information and it will guide the Language model to create a customized description.
Prompt templates are essential for diverse applications which include content and text generation, answering queries, and providing solutions.
Developing an effective prompt template and managing a repository for different use cases is essential in the LLMOps setup. Before sending queries to the model, selecting the appropriate prompt template is a primary step in the pre-processing phase.
For few-shot prompting, templates must include various examples displaying the task or desired response style.
In chain-of-thought reasoning, prompt templates must carefully outline a step-wise thought process. These templates guide the LLM to gain a systematic approach to dividing complex problems into simple steps. Chain of thought reasoning can be enhanced by incorporating external information sources, specifically in frameworks such as LangChain. In this case, if the model’s existing knowledge base is not enough, it can retrieve information from the internet.
Please note, that A/B testing of prompts is highly beneficial for both few-shot prompting and chain-of-thought reasoning. This entails exposing distinct user groups to different versions of the prompt and measuring their performance objectively. Through the analysis of performance data, the company.
Deployment & Monitoring Of LLM Model
Once your model is trained and fine-tuned up to the satisfactory mark, the next step is deploying it. Deployment within LLMOps makes the language model accessible for use in the production environment. Moving the model out of its training environment and integrating it into the production infrastructure are the two steps involved in this transition. We have given a diagram below that demonstrates the process for you:
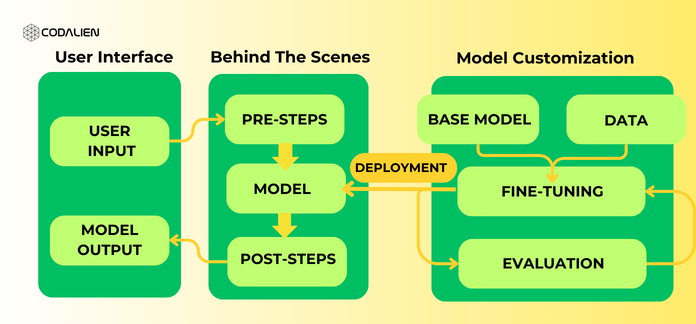
The deployment of the model also includes setting up the interface that will be used to interact with the model when it is deployed to production. Usually, the interface is based on your model’s processing mode:
Real-time Processing:
For applications requiring real-time interactions like chatting applications, we need to deploy the model in a manner that allows instant processing of data and generation of output.. The best way to achieve this is to create an Application Programming Interface (API) that interfaces with the model. You can use libraries like Flask to seamlessly create API interfaces for your model.
You can deploy the APIs on cloud platforms or web servers to ensure that users or systems that can access them interact with the model. Your LLMOps setup should ensure that the API can handle the anticipated load while considering factors like scaling, load balancing, and failover mechanisms.
Batch Prediction:
In many use cases, batch prediction serves as a good alternative to real-time prediction in cases where immediate response isn’t required. Let’s consider a situation where a batch of customer reviews requires weekly classification. In this case, using a trained model to process the reviews in batches is indeed the best solution. To perform batch-oriented tasks, you can use various tools like Cron (in Unix-like systems) to schedule batch jobs. These jobs manage data processing, run the model on fresh data at predetermined intervals, and store the outputs.
Finally, deploying the model to the production setup normally involves model packaging and versioning:
- Packaging: It involves the process of wrapping your model and its dependencies into a deployable format which can also be used in the production environment. This might entail leveraging containerization technologies such as Docker, which contains both the model and its environment. Doing this will ensure consistency across various platforms allowing seamless deployment and utilization.
- Model Versioning: Tracking specific versions of the model is necessary, especially during model updates or retraining. Model versioning involves carefully tracking multiple iterations of your model alongside the prompt templates and training data. This methodical approach makes it easier to keep a detailed record, allowing easy maintenance and model iteration over time.
CI/CD Pipelines
Continuous Integration (CI) and Continuous delivery (CD) pipelines automate the processes involved in moving a model from the development to the production environment, ensuring the model remains reliable, updated, and deployed efficiently. Continuous Integration (CI) ensures to automatically test the new code or model modifications (such as hyperparameter tweaking, model architecture modifications, or the addition of new training data) in LLMOps. This also includes running unit tests, integration tests, and any other checks to verify the changes do not hamper the model’s performance or break it. In simple words, CI serves as a constant surveillance, keeping an eye on the model’s health and making sure it continues to be robust and dependable.
Once you’ve successfully executed the changes in the CI phase, you need to initiate the CD phase. This phase automates the deployment of the model to the product environment, ensuring swift deployment while keeping LLMOps production setup seamless. Moreover, CD simplifies the process of rolling back to earlier versions in case issues arise in the production environment. By reducing downtime and increasing service dependability, this feature makes sure that LLMOps can continuously supply high-quality language models without experiencing any problems.
Orchestration
One crucial aspect that is still missing from our discussion of LLMOps: is the orchestration of components to establish a logical sequence of steps. In LLMOps, orchestration includes strategic planning and management of operations forming a defined workflow. In simple words, it is all about defining the sequence of operations, managing data flow between various components, and automating the execution of tasks to make sure that model development and deployment happen effectively.
We generally handle orchestration by writing configuration files, which typically use YAML (Yet Another Markup Language). These configuration files outline multiple parts of the process, their sequence, and settings for each step. To simplify and clarify things, developers often use Domain Specific Languages (DSLs) in these files because they provide a specialized syntax and user-friendly way to define workflows.
In conclusion, this automates workflows to ensure that once the process begins, all steps flow smoothly without needing manual interference. This reduces the need for manual tasks and helps prevent potential issues.
Optimizing Language Model Operations: Advanced Strategies and Best Practices
In this blog, we have discussed the fundamental elements of an LLMOps infrastructure and their importance. But please note that incorporating advanced techniques can further boost the performance of your LLMOps setup:
- Use High-Performance Resources: Utilizing high-performance computing resources such as GPUs or TPUs can boost the interference speeds, remarkably decreasing latency in comparison to CPU-based setups. Choosing the best hardware is vital when building an LLMOps infrastructure.
- Load-Balancing: It is advisable to deploy multiple instances of the same model for services such as ChatGPT which are widely used in multiple regions. This allows the distribution of incoming requests in various models, thus it’s essential to know about the no. of available models and their computing capabilities at a given time within your LLMOps setup.
- Geographical Distribution: Performance can be improved by placing relevant LLMOps infrastructure components and hosting models closer to end users in various nations. The process entails streamlining data transmission protocols and data serialization to guarantee quick and effective data flow between users, the infrastructure, and the models.
Securing LLMOps: Addressing Security Concerns in Language Model Operations
Building a reliable service requires ensuring user confidentiality and data privacy within our LLMOps infrastructure. Hence, It is essential to implement robust data anonymization techniques to achieve this. You need to implement various approaches such as differential privacy, k-anonymity, and data masking to prevent training data from revealing sensitive personal data collected during dataset creation. Moreover, if the user data is used to refine the models iteratively, the users should be informed and their data must be anonymized before including in the fine-tuning process.
Private user data, including ChatGPT chat history, is stored on your system with security concerns in mind. Following data protection laws like GDPR is essential, and we must make sure that all data is processed securely and sent via encrypted channels within our infrastructure.
Furthermore, maintaining robust access controls throughout the entire LLMOps infrastructure is crucial. Only authorized personnel should have access to the model, data, and training environment to prevent any possible leaks that could compromise user privacy. By prioritizing data privacy and implementing stringent security measures, we can establish a trustworthy LLMOps infrastructure that instills user confidence and prioritizes user protection.
Conclusion
Wrapping up our comprehensive LLMOps guide, it’s evident that the robust frameworks utilized in LLMOps infrastructure form the foundation of any successful LLM service. From streamlining behind-the-scene processes to maintaining reliability. security and scalability.
Operationalizing LLMOps plays a pivotal role in delivering effective and user-centric LLM-as-a-service solutions. In this blog, first, we’ve dived into the journey of prompt from the time when a user enters his query and submits it to the model till the response is received. LLMOps ensures that all these “behind the scenes” steps are streamlined and efficient.
Then, we’ve also looked into the details of how model training, deployment, monitoring, and maintenance are all included in LLMOps. LLMOps ensure the scalability and reliability of our LLM-based systems by including scaling resources to effectively handle fluctuating demands. We have also discussed best practices to improve our LLMOps infrastructure.
Lastly, we have recognized that LLMOps play a role in maintaining the security and integrity of LLMs-as-a-service. RobustLLMOps processes are necessary to maintain strict security measures, guarantee data privacy, and ensure compliance with regulatory norms because these models frequently handle sensitive data.
With this article, We hope we have enlightened you on one key point: LLMOps is a strategic asset that adds value, reliability, and sustainability to LLMs a service, in addition to being an operational need.
In addition to understanding the fundamentals of LLMOps, it’s crucial to explore practical applications of AI models in business settings. Check out our blog on ‘How to Build an AI Model for Business‘ for valuable insights into leveraging AI effectively in your organization.